Comme dans cette vidéo de Léo Grasset, qui tient la chaîne Dirty Biology, vous avez pu entendre de « progression exponentielle » du nombre de cas atteints par le SARS-CoV-2:
Que l’on soit clair, une courbe exponentielle, c’est ça:
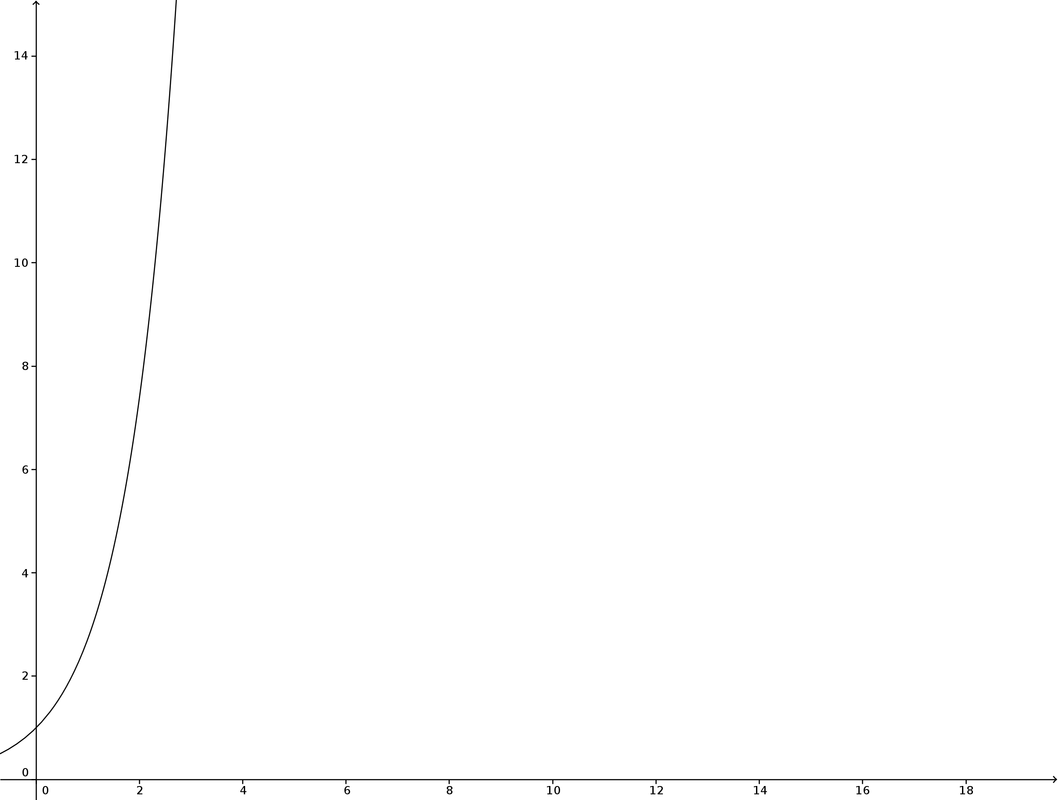
Or une courbe épidémiologique n’a pas du tout cette progression. Elle va d’abord contaminer de plus en plus de personnes puis se résorber progressivement comme la courbe ci-dessous :
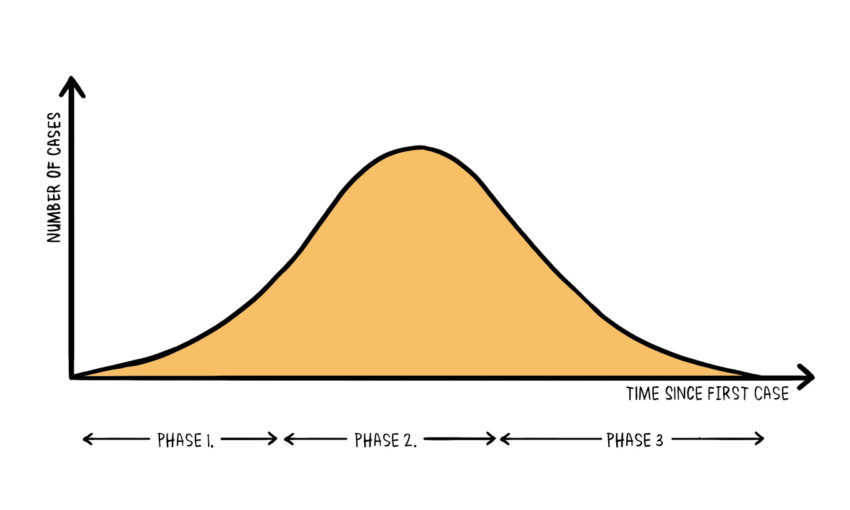
On a une courbe concave, croissante puis décroissante qui converge vers 0. Ce qu’explique l’économiste Richard Baldwin dans son article intitulé « It’s not exponential: An economist’s view of the epidemiological curve » accessible sur le site Voxeu, non sans humour :
Il ne s’agit pas d’un processus de croissance exponentielle. Pourquoi ? Si les zombies ne meurent jamais et ne se rétablissent jamais, ils finissent par avoir du mal à trouver de nouvelles victimes. De plus, les survivants non zombies commencent à prendre des mesures de confinement extrêmes qui réduisent le taux d’infection – et produisent un grand spectacle. Le COVID-19 n’est pas la maladie des zombies – ce n’est pas une surprise – mais il peut nous aider à réfléchir aux caractéristiques épidémiologiques du virus.
Richard Baldwin
La courbe épidémiologique est représentée ci-haut avec une forme en cloche similaire à une gaussienne. Il s’agit d’une simplification. C’est vrai qu’elle renseigne sur la probabilité d’être contaminée (il y a plus de chances de tomber malade au moment du pic). Néanmoins, les courbes épidémiologiques empiriques sont asymétriques vers la droite. L’épidémie de COVID-19 démarre assez rapidement mais elle met un certain temps à s’éteindre. La queue à gauche est courte alors que celle à droite à tendance à être plus étalée. Vous pouvez vous référez à cette discussion sur stack exchange pour plus d’information.
La vidéo de Léo Grasset ajoute doublement à la confusion :
- Il parle d’une progression exponentielle des cas de SARS-CoV-2 pendant toute la première partie de la vidéo. Il faut attendre la 13e minute (sur 19) pour voir des courbes épidémiologiques. C’est au moment où il introduit un article du célèbre épidémiologiste Neil Ferguson et de son équipe, de l’Imperial college, pour parler de l’efficacité des mesures de confinement.
- Et Léo Grasset continue de parler de phénomène exponentiel même après avoir montré ces courbes épidémiologiques.
Pourquoi cette confusion ?
Il est vrai que le début de l’épidémie ressemble à une courbe exponentielle. On peut modéliser son début comme celui d’une suite géométrique.Soit \(U_n\) une suite géométrique qui représente le nombre de malades à la période n. Si un malade contamine \(r\) personnes, on peut dire que le nombre de personnes contaminées à la période n (\(U_n\)) est le produit de \(r\) et du nombre de personnes contaminées à la période précédente qui est n-1 (\(U_{n-1}\)). Soit:
\(U_n = U_{n-1} \times r\)\(r\) est aussi appelé raison. On considère ici seulement des suites avec des valeurs positives. Si la raison est strictement supérieure à 1, la suite est dite « divergente », elle croit indéfiniment. A l’inverse, si la raison est strictement inférieure à 1, la suite va converger vers 0. Les personnes déjà familières avec l’épidémiologie noteront que la raison d’une suite géométrique ressemble beaucoup au \(r_0\), le taux de reproduction de base d’une maladie. La fonction exponentielle permet de généraliser la suite géométrique au cas continu. L’intérêt de la modélisation continue est de pouvoir modéliser un phénomène avec des courbes au lieu d’utiliser des histogrammes. C’est plus facile quantitativement à utiliser quand on fait un modèle.
Modèles SI et SIR: expliquer la forme de la courbe épidémiologique
Ici, on raisonne en modèle SI. Il y a juste des personnes susceptibles d’être infectées (S) ou déjà infectées (I). En réalité, il y a des personnes qui se sont remises de la maladie (R). On parle de modèle SIR. On peut représenter sous ces équations simples en forme discrète les évolutions de chaque variable à la période n au sein d’une population N. La période n peut être mesurée dans une unité de temps quelconque. Si on choisit la journée comme unité de temps, la période n représente la énième journée. Maintenant, décrivons les équations de notre modèle SIR discret.
Le nombre de personnes contaminables (S)
Le nombre de personnes susceptible d’être contaminées à la période n (\(S_n\)) dépend de la proportion de la population infectée (\(\frac{I_{n-1}}{N} \)) et du nombre \(\beta\) qui mesure combien de personnes susceptibles d’être contaminées sont infectées par une personne atteinte du virus lors de la période n :
\(S_n = (1-\beta\times\frac{I_{n-1}}{N})\times\,S_{n-1}\)A chaque période, le nombre de personnes susceptibles d’être infectées diminue. On retranche le nombre de personnes infectées. Pour conserver un modèle simple, on garde le même nombre moyen de personnes contaminées pour chaque période \(\beta\). Si une période est une journée, \(\beta\) est le nombre de personnes que contamine une personne infectée en moyenne par jour. Pour que le modèle soit valide mathématiquement, il faut que \(0<S_n<N\) soit \(0<1-\beta\times\frac{I_{n-1}}{N} <1\). Le nombre de personnes susceptibles d’être contaminées ne peut pas être négatif et il ne peut que décroître. Rappelez-vous les zombies évoqués par Richard Baldwin plus haut. Les personnes susceptibles d’être contaminées ne peuvent faire la transition que vers l’état infectée. On représente cette transition au niveau de la population avec l’équation suivante.
Le nombre de personnes infectées (I)
Le nombre de personnes infectées \(I_n\) croît avec le produit de le nombre de personnes contaminées par une personne infectée au cours d’une période, défini ci-haut (\(\beta\)), et de la proportion du nombre de personnes susceptibles d’être contaminées au sein de la population (\(\frac{S_{n-1}}{N} \)) :
\(I_n = (1+\beta\times\frac{S_{n-1}}{N}-\mu)\times\,I_{n-1}\)Le nombre de personnes infectées \(I_n\) croît avec le produit de la probabilité de contamination d’un individu défini ci-haut (\(\beta\)) et de la proportion du nombre de personnes susceptibles d’être contaminées au sein de la population (\(\frac{S_{n-1}}{N} \)). Par contre, \(I_n\) décroît avec le taux de personnes remises de la maladie (\(\mu\)). Par définition, \(0<\mu<1\). On peut calculer le nombre moyen de période, M, où une personne infectée sera remise de sa maladie. On en déduit que :
\(M\times\mu = 1 \)Ce qui donne :
\(M = \frac{1}{\mu}\)Le ratio \(\frac{1}{\mu}\) mesure la durée d’infection. Si elle est en nombre de jours, une personne contaminée sera infectée et donc contaminante pendant \(\frac{1}{\mu}\) jours.
Dans ce modèle, la seule issue possible est la guérison. Il s’agit d’une simplification. On ne modélise pas ici le nombre de morts (ce que d’autres modèles comme le modèle SEIRD, évoqué plus bas, font).
Le nombre de personnes remises (R)
Le nombre de personnes remises de la maladies est modélisée par l’équation suivante :
\(R_n = R_{n-1} + \mu\times\,I_{n-1}\)Le nombre de personnes remises de la maladie \(R_n\) est croissant. Il ne peut qu’augmenter. On raisonne à population constante N. Cette dernière doit être constante à la somme des populations dans les différents états possibles (susceptibles d’être infectés, infectés ou remis) :
\(S_n+I_n+R_n=N\)Croissance et décroissance d’une épidémie dans le modèle SIR
La raison de la suite géométrique \(I_n\) est égale à \(1+\beta\times\frac{S_{n-1}}{N}-\mu\).On l’appelle aussi facteur de reproduction à la période n (\(r_n\)). Soit :
\(r_n = 1 + \beta\times\frac{S_{n-1}}{N}-\mu \)On remarque que \(I_n\) devient décroissant quand:
\(I_n<I_{n-1}\)L’équation ci-haut décrit l’état où le nombre de personnes infectées à une période n (\(I_n \)) est inférieure au nombre de la période précédente (\(I_{n-1}\)). Ce qui correspond à un taux de reproduction à la période n inférieur à 1:
\(r_n<1\)Cela nous donne le résultat suivant :
\(\frac{S_{n-1}}{N} < \frac{\mu}{\beta}\)\(\frac{S_{n-1}}{N}\) est le ratio de personnes susceptibles d’être infectées à la période n-1. Plus de personnes deviennent infectées dans le temps et par la suite guéries de cette maladie, plus le nombre de personnes susceptibles d’être infectées va baisser. Si \(\mu\) et \(\beta\) sont constants, le taux de reproduction est décroissant dans le temps. C’est pour cette raison que l’on obtient une courbe en forme de cloche croissante puis décroissante, et non exponentielle. Pour représenter l’effet du confinement, on peut faire varier le facteur de contamination (\(\beta\)). Le confinement diminue cette valeur. A l’inverse, le déconfinement l’augmente d’où un potentiel effet rebond. C’est cette valeur que les épidémiologistes font varier dans le temps. \(\mu\) peut aussi être modélisé dans le but de mesurer l’efficacité d’un système de soins à traiter les gens infectés. Le ratio \(\frac{\mu}{\beta}\) détermine le taux de l’immunité de groupe. Cette valeur est le point d’inflexion à partir de laquelle le nombre de cas va décroître pour converger vers 0.
Le facteur de reproduction de base (\(r_0\)) est un cas particulier du taux de reproduction qu’on a défini pour une période n (\(r_n\)). Il s’agit du taux de reproduction quand toute la population est saine. Dans ce cas, on obtient :
à l’exception d’une personne est infectée. C’est le taux de reproduction à la période 0 d’où le nom de \(r_0\). Dans la spécification discrète de notre modèle, cela donne:
\(r_0 = 1 + \beta -\mu\)Le facteur de reproduction de base peut être exprimée en fonction du nombre reproduction de base (le fameux R0). Pour ne pas confondre avec la suite \(R_n\), on notera le nombre de reproduction de base \(\rho_0\) (\(\rho\) est la lettre grecque rho). On définit le nombre de reproduction de base tel que la moyenne du nombre de personnes contaminées par une personne infectée. Il s’agit du produit entre le nombre moyen de personnes contaminées par jour (\(\beta\)) et de la durée moyenne de contamination (\(\frac{1}{\mu}\)). On obtient :
\(\rho_0 = \frac{\beta}{\mu}\)L’immunité de groupe étant atteinte quand \(\frac{S_{n-1}}{N} < \frac{\mu}{\beta}\), on peut réécrire \(\frac{S_{n-1}}{N} < \frac{1}{\rho_0}\). Les épidémiologistes utilisent le \(\rho_0\) car son inverse donne directement l’immunité de groupe et en même temps, il donne le nombre moyen de personnes contaminées en plus quand on introduit une personne infectée dans la population. On obtient la relation suivante entre le facteur de reproduction de base et le nombre de reproduction de base:
\(r_0 = \mu\times(\frac{1}{\mu}+\rho-1)\)
Et en n:
Réexprimer le facteur de reproduction en fonction du nombre de reproduction fait ressortir le ratio \(\frac{1}{\mu}\) qui nous donne le nombre de jours où une personne infectée peut contaminer les personnes susceptibles de l’être. Le taux de reproduction en n (\(\rho_n\)) est défini comme :
\(\rho_n = \rho_0\times\frac{S_{n-1}}{N}\)On constate que quand l’immunité de groupe est atteinte. Ce qui est vérifiée en \(\frac{S_{n-1}}{N}=\frac{\mu}{\beta}\), on constate que :
\(r_n=\rho_n=1\)Utiliser le facteur ou le nombre de reproduction de base est donc équivalent. Mathématiquement, cela s’explique par le fait que \(r_n\) est une fonction croissante de \(\rho_n\). Dans le modèle continu, il est plutôt coutume d’utiliser le nombre de reproduction de base. Pour notre modèle discret, on se réfère au facteur de reproduction de base car il nous permet d’approximer le nombre de personnes infectées simplement par une suite géométrique en début d’épidémie.
Approximation du nombre de personnes infectées en début d’épidémie
Supposons que nous introduisons seulement une personne infectée en période 0 soit \(I_0=1\). Nous avons la période 1 le facteur de reproduction suivant :
\(r_1 = 1+ \beta\times\frac{N-1}{N} -\mu\)Maintenant faisons l’hypothèse suivante, N est très grand donc ça revient à dire que :
\(\frac{N-1}{N}\approx 1\)Dans ce cas, \(r_1\approx r_0\) et \(I_1 \approx r_0\times I_0 \approx r_0\)
Ce sera pareil pour tout entier naturel k où le ratio \(\frac{N- r^k_0 }{N}\approx 1\). Ce qui fait que pour k petit, on peut approximer \(I_n\) avec la une suite géométrique ayant comme raison \(r_0\) tel que :
\(I_k \approx I_0 \times r^k_0 \approx r^k_0 \) si \(\frac{N- r^k_0 }{N}\approx 1\)
Pour la version en temps continu du modèle SIR, l’équivalent est la fonction exponentielle. Or le nombre de personnes infectées décroît quand le taux de personnes susceptibles d’être infectées à une période n (\(\frac{S_{n}}{N}\)) est inférieur au ratio \(\frac{\mu}{\beta}\). Ce dernier varie donc dans le sens opposé \(r_0\). Plus le \(r_0\) est grand, plus le pic de l’épidémie correspondra à une proportion de personnes susceptibles d’être infectées qui est faible. Et donc par corollaire, le pic de l’épidémie correspondra à un taux de personnes ayant été infectées dans la population plus élevé. Ce pic est l’immunité de groupe défini plus haut par le ratio \(\frac{\mu}{\beta}\). Plus une maladie se soigne facilement (\(\mu\) est élevé), plus le \(r_0\) sera bas et donc plus le taux de personnes qui aura contracté la maladie sera faible pour atteindre l’immunité de groupe. A l’inverse, plus le facteur de contamination (\(\beta\)) est grand, plus le \(r_0\) sera élevé et donc plus le taux de personnes qui aura contracté la maladie sera grand pour atteindre l’immunité de groupe.
Résumé sur le concept d’immunité de groupe par Nicolas Martin.
La modélisation discrète dans ce billet est une adaptation du cas continu vulgarisé par l’excellent article de Bruno Gonçalves intitulé « Epidemic Modeling 101: Or why your CoVID-19 exponential fits are wrong« . On y trouve une présentation du modèle SIR avec plein de graphiques (dont la représentation du modèle SIR présente dans la vidéo de Léo Grasset à 12:19). Bruno Goncalves a aussi publié une 2e partie intitulée « Epidemic Modeling 102: All CoVID-19 models are wrong, but some are useful » où il présente le modèle SEIRD qui permet de modéliser les personnes asymptotiques et les décès.
Les limites des modèles doivent nous inciter au recul
C’est aussi l’autre point qui m’a choqué dans la vidéo de Léo Grasset. Il ne prend aucune distance quand il présente ses prédictions du modèle SIR qu’il utilise. C’est un modèle jouet … De plus, le vidéaste parle des personnes décédées mais elles ne sont pas prises en compte dans le modèle SIR (contrairement au modele SEIRD par exemple qui modélisent explicitement le nombre personnes asymptomatiques et décédées). Son manque de rigueur se retrouve aussi quand il cite le très approximatif Tomas Pueyo qui justement fait une simple extrapolation exponentielle avec des fourchettes très larges.
Critique de l’article medium de Tomas Pueyo, Coronavirus: why you must act now.
Léo Grasset semble avoir surtout été inspiré par le 2e article de Tomas Pueyo, intitulé « Coronavirus: the Hammer and the Dance« ,qui est plus nuancé que le premier. Il a découvert depuis les modèles SIR et il a une biographie variée. Néanmoins, il continue de parler de croissance exponentielle. Par contre, on retrouve toujours le sensationnalisme irritant de Pueyo comme dans son graphique 15 ci-dessous :
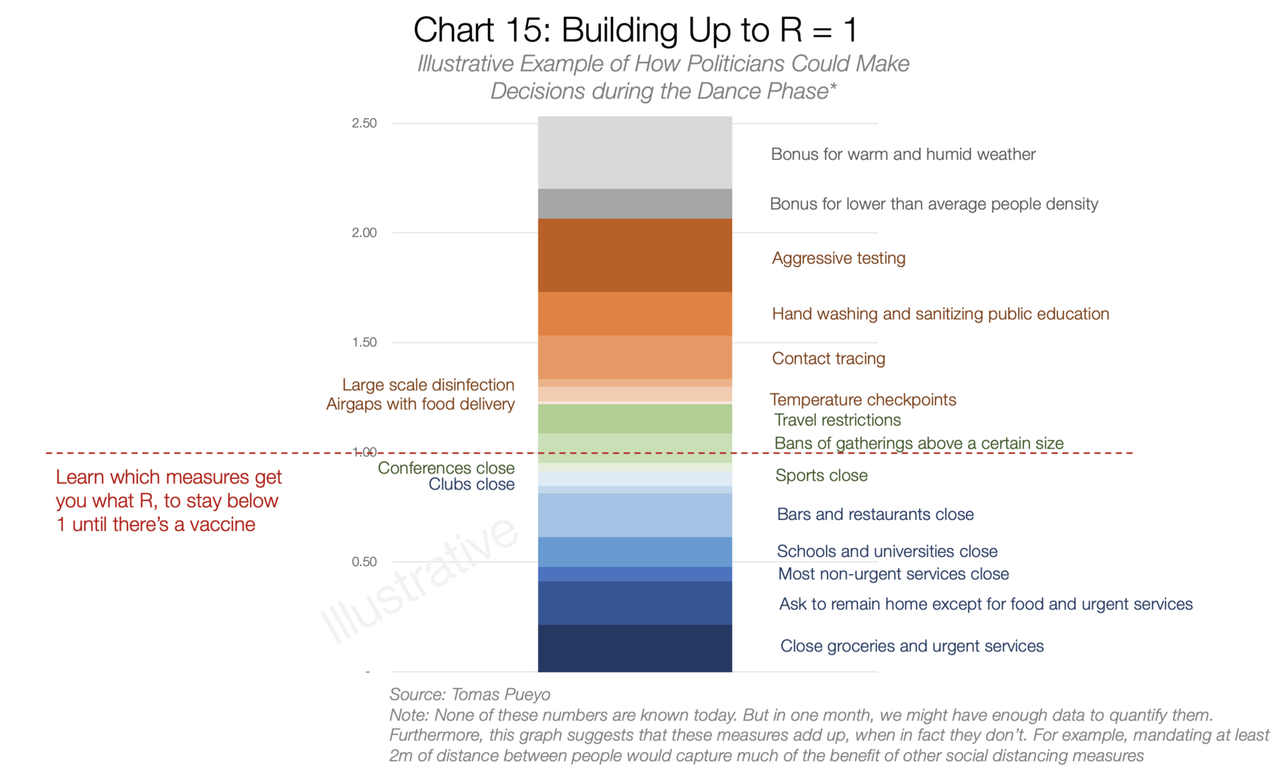
C’est quoi l’intérêt de faire un classement de mesures qui ne repose sur rien ? On peut aussi être sceptique devant son modèle d’aide à la décision au graphique 16 qui préconise un R0 optimal en fonction du coût supposée des mesures. Au-delà d’être une analyse coût-bénéfice frustre (de simples chiffrages monétaires au lieu d’une analyse de la satifasaction), l’exemple est complètement ad-hoc comme l’auteur le précise lui-même. Par contre, en lisant l’article de Tomas Pueyo, je suis tombé sur l’article de Shen, Taleb et Bar-Yam qui critique férocement le modèle de l’équipe de Ferguson et plus generalement les modeles de type SIR. Je ne vais pas rentrer dans ce débat qui dépasse le billet de ce blog. Mais un paragraphe des auteurs est très pertinent:
Si les efforts de modélisation de la réponse sociale sont importants, l’omission d’aspects critiques de la réponse donne des réactions incorrectes. Se concentrer sur les détails mais utiliser des hypothèses incorrectes donne de mauvais conseils politiques. Lorsque des vies sont en jeu, il est essentiel que la science adhère à des normes plus élevées.
Shen, Taleb et Bar-Yam.
Vous pouvez aussi retrouver une critique des travaux de Neil Ferguson et des modèles SIR dans la tribune du médecin épidémiologiste britannique, le Dr Roland Salmon dans le journal Le Monde. Ce dernier souligne les nombreuses erreurs de prédictions passées de Neil Ferguson et de son équipe de l’imperial college.
L’utilisation de modèles avec des prédictions apocalyptiques finit par inquiéter au sein même des sociétés savantes. Martin Goodson, qui tient la chaire de Data Science au sein de la Royal Statistical Society, a publié un article intitulé « All models are wrong, but some are completely wrong » sur le blog de la chaire. Il reprend l’exemple d’un article catastrophiste du Financial Times qui proposait une modélisation aboutissant à un résultat stupéfiant: la moitie de la population britannique pourrait être infectée par le COVID-19. Il suffisait de changer les valeurs d’un paramètre pour obtenir des résultats radicalement différents, le taux de cas sévères parmi les personnes infectées. Il s’est avéré que le Financial Times avait choisi comme hypothèse un taux anormalement haut pour justifier son article sensationnaliste. Selon Martin Goodson, le risque est de donner du grain à moudre aux sceptiques et de se retrouver dans la même situation que les climatologues qui font face à une opposition très virulente. C’est le cas aux États-Unis et au Brésil où les chefs d’État semblent attirés par de fausses théories sur le virus. Martin Goodson suggère six règles:
- Règle 1. Les scientifiques et les journalistes doivent exprimer le niveau d’incertitude associé à une prévision.
- Règle 2. Les journalistes doivent obtenir des citations d’autres experts avant de publier.
- Règle 3. Les scientifiques doivent décrire clairement les données et hypothèses essentielles de leurs modèles.
- Article 4. Être aussi transparent que possible.
- Article 5. Les décideurs politiques devraient utiliser plusieurs modèles pour informer les politiques.
- Article 6. Indiquer quand un modèle a été produit par une personne sans antécédents en matière de maladies infectieuses.
Views: 2467